文言文BERT:李白用的词都没我选得好
萧箫 发自 凹非寺
量子位 报道 | 公众号 QbitAI
都说GPT-3能接人话,补充上下文关系,中文版的“填词大师”你见过没?

不仅是中文版,这个“填词大师”甚至还是从古代穿越过来的文言文版。
这是两个来自北理工的小哥做出的模型GuwenBERT,经过训练后的模型,不仅能自动帮助文言文断句,还能帮你思考被遮住的词语到底是什么。(真没有用原诗骗你)

要是这个模型去参加高考,文言文断句、诗词背诵部分,岂不是都能拿满分?
来看看它是怎么被做出来的~
文言文版BERT,填词断句样样通
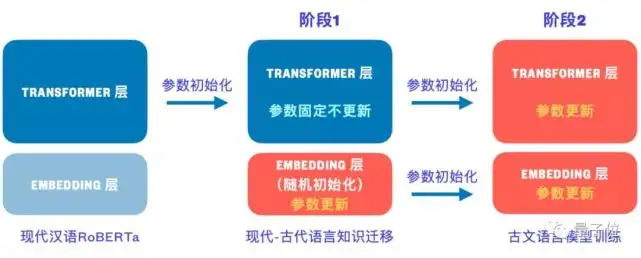
GuwenBERT,是在中文BERT-wwm模型的基础上,利用古文数据集训练出来的。

中文BERT-wwm(基于全词遮罩技术的中文预训练模型)是哈工大和讯飞联合发表的模型,在中文BERT的基础上,修改了预训练阶段的训练样本生成策略。
全词遮罩(Whole Word Masking),指原来的遮罩(mask)只随机遮一个字,现在则会对一个词的所有字进行遮罩。

但中文BERT-wwm,是针对现代汉语训练的模型。
经受过文言文“毒打”的小伙伴都知道,古文不仅词法与现代汉语中多存在不同,而且没有断句,理解起来费神费力。
想要在大量古籍中按图索骥,快速查找到想要的资料,更是难上加难。
为此,GuwenBERT横空出世,根据已有的现代汉语模型,用古文数据集训练出了文言文预训练模型。预训练的过程是这样的:
目前,这个模型已经给出了样本,在线就能一试文言文版BERT的功力。
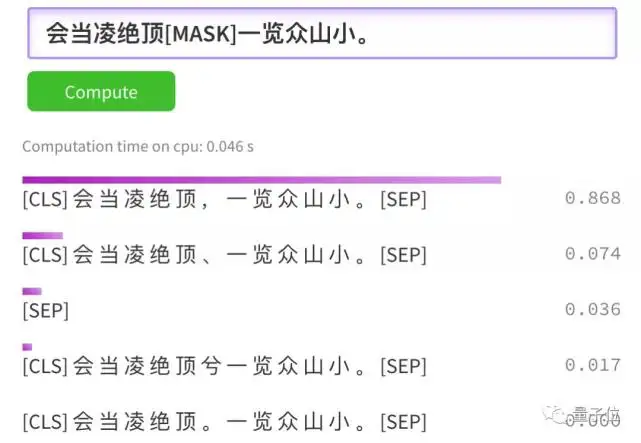
调戏Demo的方法是,随便给一句古文,用[MASK]遮住其中一个字、或是一个标点,让GuwenBERT来猜猜看,你遮住的到底是什么。
例如,遮住一个逗号,看文言文会不会断句。BERT在思考了不到一秒后,就给出了自己的答案:
至于填词方面,文言文BERT的表现也很优秀,在思考了一会后,填上了正确的词语。

是不是感觉有点简单?我们用课文来试一下:

效果竟然也不错,要是这样的理解能力去参加高考,岂不是就能拿个默写部分的满分了?
其实不然,这个文言文BERT,并不是根据记忆来判断如何填词,只是根据训练后的模型,来预测“概率最大的字”。
于是在测试过程中,出现了一些神奇的事情:这个文言文BERT,不仅能接梗造词,甚至还给李白诗中的字“推荐”了更好的替代者。
接梗造词样样会,李白的诗也能改
举个例子,即使输入的不是原来的诗句,文言文BERT也同样能预测出被遮住的字,不仅能随便接梗,还面不改色心不跳。
例如,“垂死病中惊坐起,笑问客从何处来”也能接……(原诗是?)

一旦涉及动词的选取,GuwenBERT的预测就更加难以捉摸,因为可选的范围太大了。(中文博大精深)
例如,将“不及汪伦送我情”的“送”字遮住的话,GuwenBERT就开始感到迷茫,即使是预测率最高的“知”,也只有15.7%的概率。
“不及汪伦知我情”,想必BERT版李白,内心一定认为汪伦是自己高山流水一般难得遇见的知音。

在断句的情况下,如果并非对仗工整的语句,GuwenBERT也要好好思考一会。

虽然文言文BERT有自己的想法,不过它还是“循规蹈矩”的,目前在测试时,语法上还没有出现太大的问题。
甚至,还能为古人们的写作提供别样的灵感。
但文言文BERT目前还只能遮罩一个字,要是多了几个,它就不跟你玩了。

不知道作者以后会不会在这方面进一步加上新功能。
作者介绍
这个文言文BERT的作者,是两位来自北理工的同学。
阎覃,来自北京理工大学,目前是计算机科学与技术专业的一名硕士生。

这位小哥在GitHub的名字是Ethan,他还特意选择了某些日期来contribution,把自己的名字拼了上去。

迟泽闻,同样来自北京理工大学,目前的研究工作主要是通过预训练来进行跨语言的自然语言生成。
这样的文言文BERT,你觉得还能用在哪些地方呢?
欢迎留言讨论~