“高大上”的密度泛函也有缺陷
密度泛函理论(DFT)是一种研究多电子体系电子结构的理论方法,是人类发展历史长河中的灵光一现,绝对属于诺奖级别的贡献。从事物理、材料科学研究的小伙伴如果用到DFT,绝对能让研究提升一个档次。
简单来说,微观体系粒子运动遵循薛定谔方程,只要得到方程的解——波函数就能准确描述微观体系,以至于狄拉克说:“大部分的物理问题和所有的化学问题在原理上已经解决,剩下的问题就是求解薛定谔方程”,但他又说:“困难只在于运用这些定律的方程太复杂,无法求解”。复杂的原因在于电子、原子核之间的相互作用难以描述。
为了能求解薛定谔方程,人们提出了Hohenberg-Kohn定理(H-K),用电子密度取代波函数来计算多体体系的基态能量,用交换关联泛函表示多体体系中难以描述的相互作用和所有误差,就这就极大简化了计算过程。
H-K定理指出基态能量和电子密度之间的确存在准确的泛函关系,但这个关系是啥,谁也不知道,因为交换关联泛函没人能说得清楚。这就是DFT的不足之处。
用人工智能来“猜测”更准确的相互作用
Deepmind公司的James Kirkpatrick和马普固态研究所的Aron J. Cohen在考虑了DFT中分数电荷(FC)和分数自旋(FS)两种约束后,提出了一种深度学习网络Deepmind21(DM21),更好描述了电子密度和基态能量之间的关系。DM21在主族原子和分子上的预测精度要好于已有的方法,可以更加准确描述带电荷的DNA碱基对、氢链和双自由基过渡态等复杂体系。同时,DM21非常依赖于数据和约束,只要不断提高数据质量、考虑更多的约束,就能不断提高预测性能,简直就是为更准确求解薛定谔方程提供了一盏明灯。这一成果发表在了2021年12月10日的《Science》上。当天登上Nature,被评价为:DeepMind AI tackles one of chemistry’s most valuable techniques。


大量训练,准确预测
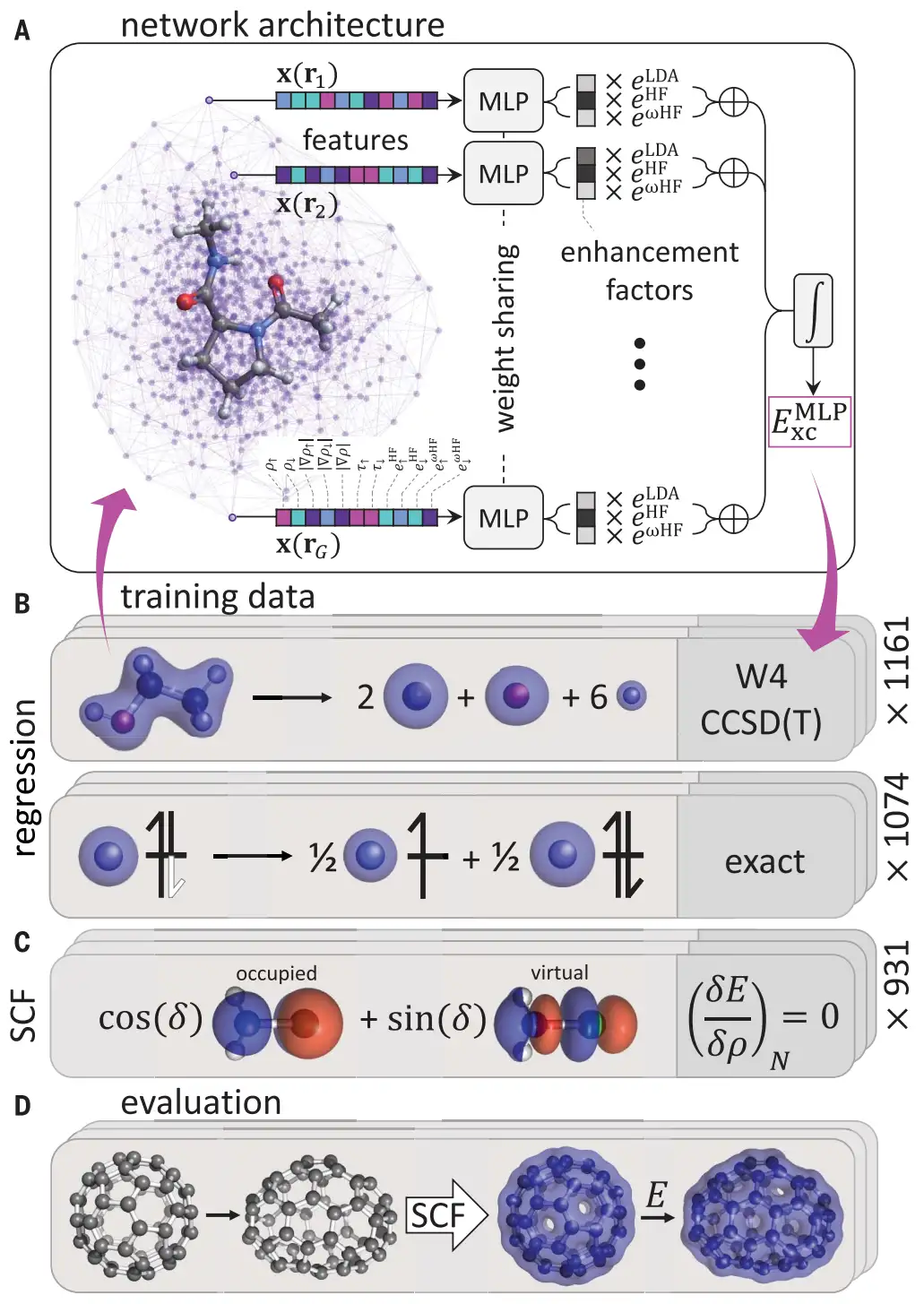
图1. DM21的结构和训练过程。
研究者以占据的Kohn-Sham(KS)轨道的局部和非局部特征作为网络输入,以交换相关能量的回归损失和梯度正则化项之和作为输出,采用多层感知机(MLP)计算局部能量。对于回归损失,他们使用固定密度的2235个反应作为数据集,通过最小二乘法实现了固定密度与反应能量的映射(图1B)。在计算能量梯度时,对交换相关能量进行微分,并结合了摄动理论(图1C)。

图2. 分数约束解决了电荷和自旋局域和离域误差。
网络训练好后,研究者对比了DM21与传统的B3LYP、M06-2X和ωB97X近似方法的计算精度。发现传统方法最大问题在于按下葫芦起了瓢:要想提高FC计算精度,FS误差就会很大,反之亦然。而DM21则要准确的多。
这一结果表明,DM21并不是简单的记忆训练样本,而是在原子电荷密度数据集中发现了一些特征,并有效推广到了分子体系。
传统方法无法正确描述带电中性分子和封闭壳层中性分子中键的断裂,FC误差通过离域电荷人为降低了能量,即使在无限分离的情况下带电分子也是被束缚的,这就是DFT中电荷离域误差的本质。而DM21则预测了正确的渐近趋势(图2D)。
三个领域碾压传统DFT方法
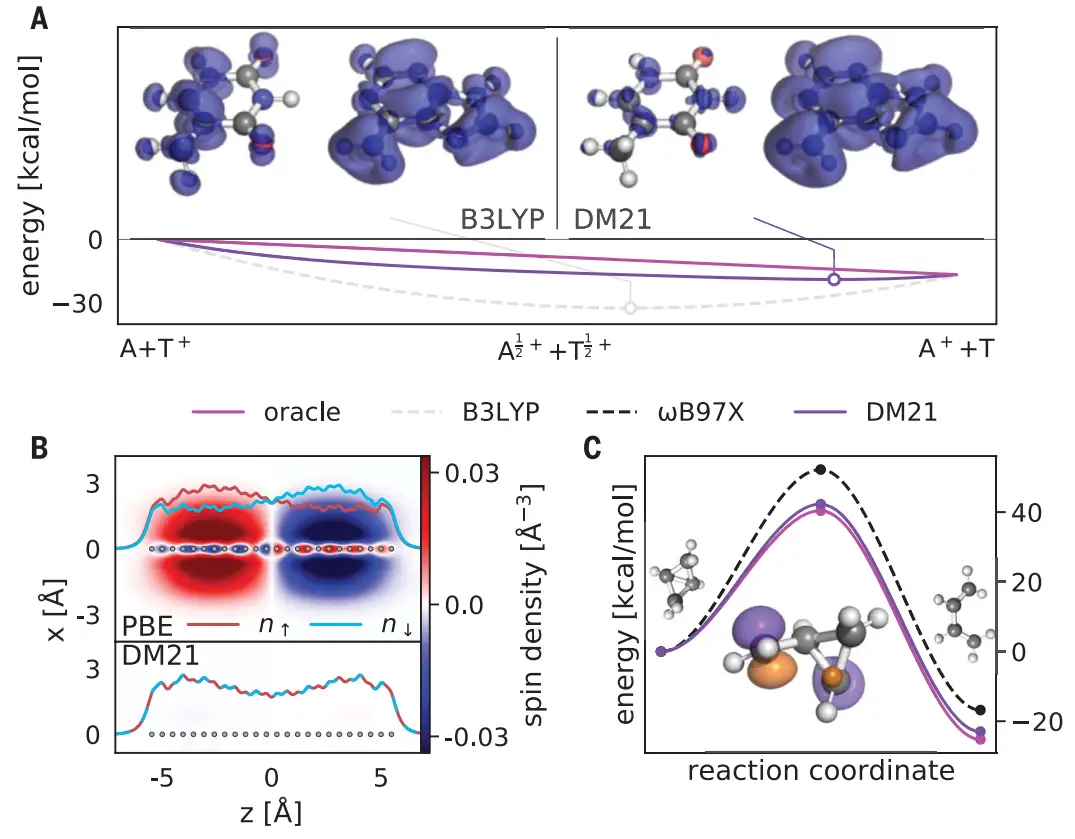
图3. DM21在DNA、压缩氢链和开环反应中的应用。
随后,研究者将DM21应用于计算DNA碱基对中的电荷离域,压缩氢链的磁性,以及开环反应中间体的反应势垒。
DNA中的电荷传输意义重大,电离碱基对(腺嘌呤和胸腺嘧啶)的电荷分布如图3A所示。传统方法(如B3LYP)发现电荷密度离域在两个碱基对上,这违背了FC约束,而DM21却发现电荷仅局限在腺嘌呤上,更接近正确的FC行为。
在高度压缩的氢链中,传统无约束泛函方法将自旋局域化在反铁磁畴区域(图3B),并作为磁性相变的证据。但波函数方法却没有给出这样的结果,说明传统方法导致了对称性破缺,而DM21则预测了一个没有自旋对称性破缺的基态。
在双环丁烷的开环反应中,用M06-2X和ωB97X传统方法计算的对旋过渡态能量偏高,这是由于FS误差所致,但DM21的预测是正确的(图3C)。
外推有风险

图4.在GMTKN55测试集上验证DM21泛化能力。
最后,研究者又利用DM21在包含更多主族原子的GMTKN55测试集上进行了预测,验证DM21的泛化能力。虽然深度学习网络的外推效果不好,但从图4B依然可以看出,DM21的预测误差在所有方法中最小。
小结
为了克服传统DFT中交换关联泛函近似误差大的缺点,研究者提出了一种深度学习网络DM21,考虑了两种分数约束,通过采用2235个反应数据集对网络进行训练,显著提高了DFT的预测精度。与传统方法相比,不仅能更好的预测DNA碱基对的电荷离域、压缩氢链磁性、开环反应中间体反应势垒,在更多主族原子GMTKN55测试集上的外推结果也好于传统方法,说明DM21可以发现更多训练数据集中的特征。而且,通过不断引入新的数据和约束,可以进一步提高DFT的准确性。